
How AI Actually Works (Inside My AI Law & Policy Class, Class #2)
Welcome to day two of law school. You're enrolled in my AI Law and Policy class.

8:55 AM, Wednesday. Welcome back to Professor Farahany’s AI Law and Policy Class. Congratulations, you’re “enrolled” in the asynchronous version of my class.

Consider this your official seat in my class—except that rather than being here in person with me, you get to keep your job and skip the debt. Every Monday and Wednesday, you get to asynchronously attend my AI Law & Policy class alongside my actual Duke Law students. They’re taking notes. You should be, too.
New here? You've missed the first class. Start with Class 1 where we discussed “What is AI?” and discovered nobody really knows. Seriously, go read it first. This class builds on that foundation.
For returning students, today we’re diving into the technical architecture of large language models. By the end of this class, you’ll understand exactly why ChatGPT cited Varghese v. China Southern Airlines—a case that sounds perfect and doesn’t exist.
Fair warning: Today gets technical. But if my in-person law students can handle it, so can you. And remember – live class is 85 minutes. Take your time working through this material.
Ok, ready? Let’s start by seeing why a lawyer got sanctioned $5,000 for trusting autocomplete.
The Most Expensive Autocomplete Fail in Legal History
In May 2023, Southern District of New York, attorney Steven Schwartz filed a brief opposing a motion to dismiss. In it, he cited several cases. Varghese v. China Southern Airlines, Martinez v. Delta Airlines, and Miller v. United Airlines.
There’s a small problem. The opposing counsel couldn’t find these cases.
Because they don’t exist.
When confronted by Judge Castel, Schwartz admitted he used ChatGPT for research. When the judge asked him to verify the cases, Schwartz went back to ChatGPT and asked, “Are these cases real?” ChatGPT said yes. It then fabricated full opinions with internal citations and holdings.
Judge Castel sanctioned Schwartz and his firm $5,000, writing that the lawyer “abandoned his responsibilities” and submitted papers containing “false judicial opinions with false quotes and false internal citations.”
Why did this happen? Not because ChatGPT malfunctioned. It worked exactly as designed. Let me show you how.

The Next Token Game
I wrote on the board: “When my dog was ___”
“Give me the single next word that most likely comes next,” I said. “Write it down. Seriously.”
Your Turn
What word would you write? Think about it for 5 seconds.
My students called out their answers. “Sick!” dominated—at least five voices. Then “young,” “playing,” and from our resident cat lover, “barking.”
This is exactly how ChatGPT wrote those fake cases. It predicted “Varghese” as a plausible plaintiff name. Then “v.” because that always comes next in case names. Then “China Southern Airlines” because airline cases were contextually relevant. Then a plausible citation format. One token at a time, creating something that looks perfectly real but is completely fictional.
(Quick reminder from our first class that a “token” is a chunk of text—usually a word or part of a word. “ChatGPT” might be one token, while “attorney-client” might be split into "attorney" and "-client" as two tokens. The model processes everything as tokens, not as complete words or sentences.)
Schwartz thought ChatGPT was searching a legal database. It was just predicting the next most statistically likely token based on patterns it had seen.
Models predict the next token in a sequence iteratively. These systems can draft sophisticated legal arguments with perfect IRAC structure while having no concept of what law, justice, or argumentation actually means. It’s pure pattern matching.
Understanding Parameters and Weights
So how does this pattern matching actually work? Let me break down what’s happening inside the machine.
Before we can understand how LLMs make decisions, we need to understand what they’re made of. A large language model consists of billions of parameters.
But what is a parameter?
Think of each parameter as a tiny dial that can be turned up or down. GPT-4 has over 1.8 trillion parameters. Each dial controls how strongly one piece of information influences another.
The “weight” is how that dial is actually set—turned up high, turned down low, or somewhere in between. During training, the model learns the right setting for every single dial.

Imagine you’re a judge determining sentence severity. You have dials to adjust for different factors:
Prior convictions (dial turned HIGH—strong influence)
Defendant’s age (dial turned MEDIUM—moderate influence)
Day of the week of the crime (dial turned ZERO—no influence)
The model has billions of these dials for language patterns. During training, these dials get adjusted millions of times until the model gets good at predicting text.
Once training is done, all 1.8 trillion dial settings are locked in place. They never change again. When you use ChatGPT, it's not learning or adjusting—it's just using its frozen dial settings to predict what comes next.
So, when the model sees “The defendant breached the,” certain pre-set dials determine what happens:
Dials connecting “defendant” to legal terms: HIGH
Dials connecting “breached” to contract words: HIGH
Dials connecting “the” to everything: LOW (articles aren’t informative)
These weights determine that “contract” is a likely next word, while “banana” is unlikely. The model isn't thinking—it's just following what its 1.8 trillion frozen dial settings tell it about which words tend to follow other words.
Creating Your Own Embedding Meaning Space
Those parameters also connect to something called embeddings, a concept that often confuses people.
Every word gets converted into a list of numbers—typically 768 to 1,536 numbers per word. These numbers represent the word’s location in “meaning space.” Those 1.8 trillion parameters? They’re controlling how words move through this space, how they relate to each other, which ones get pulled together.
For me, it’s easier to have a way visualize something this to really get it. So you can simulate what we did in class like this. First grab five objects from your desk—paperclips, sticky notes, pens, whatever. Write these words or decided to assign meaning to each of them (one word per object):
JUDGE
COURT
PLAINTIFF
BANANA
FRUIT

Now arrange them on your desk based on how related they are to each other. Words with similar meanings should be closer together. Unrelated words should be farther apart from each other.
Done? You’ve just created a physical meaning-based embedding space.
In my live classroom, we acted this out. I had five students from the first row become these words. The student representing “Judge” went first, and decided to stand near the podium. “Court” then positioned themselves right next to him. “Plaintiff” found a spot nearby but was distinct from both and tried to figure out how close to court versus judge to get. “Banana” walked away to the far corner, with “Fruit” following. (And then we had a conversation about how “fruit” could take different meanings in different contexts that weren’t law).
In an actual meaning space embeddings model, instead of that space being on your desk or my classroom and using limited dimensions, it uses 1,000+ dimensions. Words that appear in similar contexts end up with similar number patterns of their assignment in that space. And the parameters—(what we are thinking of as trillions of dials)—determine exactly how close or far apart these words end up.
Let’s take a look at some actual embeddings numbers, which have way more dimensions than the three dimensions we’re used to, because we need hundreds of dimensions to map the universe of meaning:
judge: [0.21, -0.53, 0.84, 0.12, ...]
court: [0.23, -0.51, 0.81, 0.15, ...]
banana: [0.89, 0.34, -0.22, -0.91, ...]
Notice how “judge” and “court” have similar numbers? The parameters, through millions of examples, learned that these words belong together. They’re like neighbors in mathematical space. “Banana” has completely different numbers—the parameters pushed it far away because it rarely appears near legal terms.
If you really start to think about what this means, embeddings can get really dangerous for you as a budding (or practicing) lawyer. Take these terms:
motion to dismiss
motion for summary judgment
motion in limine
motion to compel
Because these all appear in similar contexts (they’re “filed,” “granted,” “denied,” involve “plaintiffs” and “defendants”), the parameters may have them positioned as neighbors in embedding space. So the AI model treats them as nearly identical.
But legally, they’re completely different:
Motion to dismiss: Even if everything plaintiff says is true, they still lose
Motion for summary judgment: The evidence shows we win
Totally different legal standards, totally different timing in a case. But at that point, the AI literally cannot tell the difference—they’re too close together in its mathematical universe.
A Quick Aside on “Reasoning” Models
Maybe you, like some of my students, are wondering about new reasoning models. Are they different?
Reasoning models still use the same transformer architecture—same attention mechanisms, parameters, and token prediction—but they’ve been trained to generate internal “reasoning” tokens before answering, essentially showing their work like a math student.
Instead of jumping straight from “When my dog was” to “sick,” a reasoning model might internally generate tokens like “I need to predict a plausible word that could follow ‘was’ in the context of a dog, common options include emotional states, ages, or conditions” before outputting “sick.”
But—and this is crucial—they’re still just predicting tokens based on patterns. They’ve simply learned to generate tokens in a pattern that looks like reasoning before generating tokens that look like answers.
This is why reasoning models can still hallucinate legal cases. It just does it with more sophisticated-sounding explanations. Instead of just citing Varghese v. China Southern Airlines, it might write: “After considering the relevant precedents in aviation liability, particularly Varghese v. China Southern Airlines, which established the doctrine of carrier strict liability...”
Same hallucination. Fancier explanation. Still completely made up.
The Transformer Architecture: Understanding Attention
Alright, let’s dig into how these models actually decide what word comes next. The breakthrough that made ChatGPT possible is called the transformer architecture, and its secret sauce is something called “attention.”
I wrote the following sentence on the board in class today:
“The witness, who was clearly nervous and had contradicted herself twice, stated that she saw the defendant.”
“Now,” I said to my class (and am now saying to you), “when the model is deciding what comes after ‘defendant,’ it needs to figure out which previous words matter most. Let’s assign weights together.”
Now you try it! Look at each word and decide: HIGH, MEDIUM, LOW, or NEAR ZERO importance for predicting what comes after “defendant”:
“saw” — What weight would you give it?
“witness” — Your weight?
“stated” — Your weight?
“nervous” — Your weight?
“and” — Your weight?
Think about it, then compare your weight assignments to what my in-person class decided:
“saw”—HIGH weight (0.8)—directly relevant (she SAW the defendant do something)
“witness”—HIGH weight (0.7)—who did the seeing
“stated”—MEDIUM weight (0.5)—speech act, somewhat relevant
“nervous”—LOW weight (0.2)—descriptive but not directly relevant to what comes next
“and”—NEAR ZERO weight (0.02)—just grammar
These attention weights tell the model that “saw the defendant” is the key phrase. So what comes next? Try it. Predict the next word.
It’s probably an action verb like “leaving,” “running,” “entering,” “shoot,” “flee.”
The attention mechanism just narrowed the universe of 50,000+ possible next words down to maybe 100 action verbs. That’s the power of attention—it focuses the model on what matters to predict the next word.
(These attention weights are different from the model’s parameters. The 1.8 trillion parameters are fixed after training. But attention weights? They’re calculated fresh for every single piece of text, using those fixed parameters. Think of parameters as the permanent rules for HOW to pay attention, while attention weights are the temporary result of applying those rules to THIS specific sentence.)
Becoming a Transformer
We then turned my entire class into a live transformer model, and you can try this, too. Grab four friends (or better still, form a study group with other virtual students in this AI Law and Policy group—seriously, meet up and try this together! (Paid subscribers have a group chat you can use to find each other).
Here’s how we set it up:
Group 1 (Input): Say a starting phrase
Group 2 (Attention): Identify which words matter most in that phrase
Group 3 (Prediction): Based on attention’s focus, suggest possible next words
Group 4 (Selection): Pick the final word
Round 1: Here’s what it might look like in your group, and how it panned out in person.
Input said: “The contract explicitly states”
Attention identified: “Contract and states are the key words!”
Prediction offered: “that, the, all, parties, nothing...”
Selection chose: “that”
Round 2: We went for another round (you should, too)
Now we had: “The contract explicitly states that”
Attention shifted: “‘That’ is crucial now—it’s setting up a clause”
Predictions: “all, parties, the, obligations, neither...”
Selection: “all”
Round 3: You can keep going!
Input: “The contract explicitly states that all”
Attention: “‘All’ needs a plural noun next”
Predictions: “parties, terms, obligations, provisions...”
Selection: “parties”
We built “The contract explicitly states that all parties” without anyone planning the full sentence. Each round, the context shifted, attention refocused, and new possibilities emerged.
That’s a transformer model. Sophisticated pattern matching, one token at a time, with no understanding of what it’s saying. It isn’t holding the entire sentence “in its head” at once. It’s building it as it goes.
The One-Word Story Game
Speaking of building text one word at a time, my children (they’re 5 and 10) claim they invented the “one-word story” game (they definitely didn’t, but don’t tell them that). We play it on car rides and at dinner—everyone adds one word to build a story together.
Try it with your family tonight. You’ll immediately see how modern AI LLMs work.
In class, our story went: “The cat was joyful and went to the shop alone but it wasn’t fun.”
“Wait,” I said at the end. How could it be “joyful but not fun?”
When you build text one word at a time, with different people (or different attention weights) controlling each word, you can lose coherent meaning. The person who added “joyful” wasn’t coordinating with the person who added “wasn’t fun.”

This is exactly why ChatGPT can cite a case for one principle on page 2, then cite the same fake case for the opposite principle on page 5. No central intelligence is tracking consistency (although there are ways to address this if that’s what you’re going for). No one’s checking if the story makes sense. Just token after token, each one locally plausible, globally nonsensical.
The Supply Chain Issue. Who’s to Blame?
We then turned to the following supply chain image that was in the assigned reading (if you want to do assigned readings, too, you can join as a “full student” with a paid subscription and get the reading assignments, too).
We then thought about the issue of when an LLM hallucinates a case, who’s responsible? Let’s trace through the seven layers:
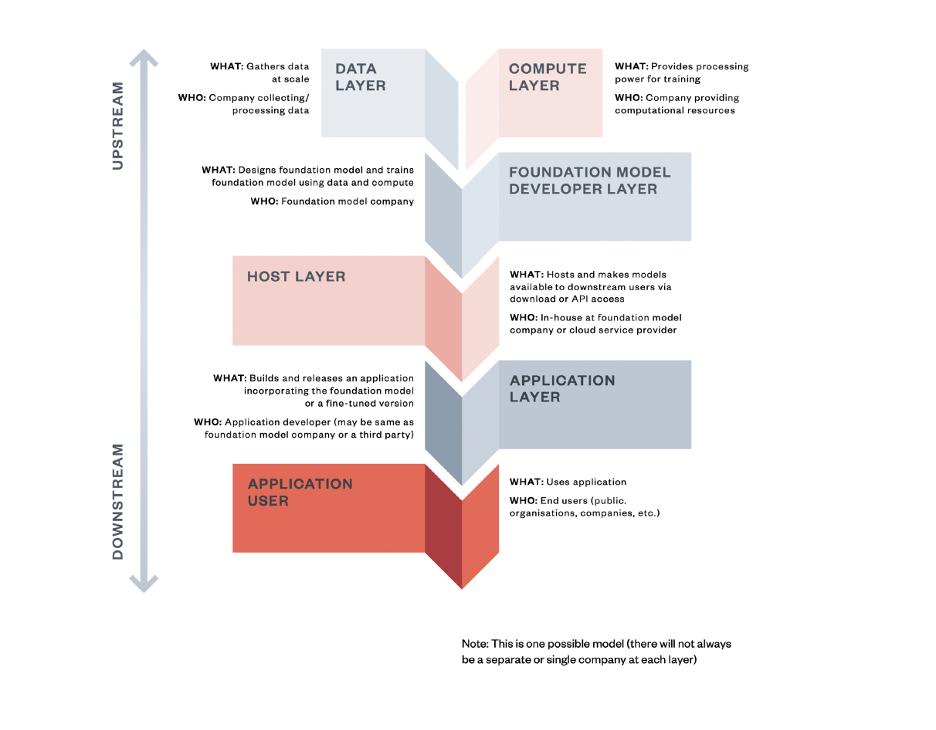
Data Providers: Web crawlers grabbed “In Smith v. Jones, the court held...” from a law school practice exam. No label saying “this is fictional.”
Compute Providers: Microsoft Azure provided the GPUs. They’re basically selling electricity—no control over what’s computed.
Foundation Model Developer: OpenAI trained the model. But with 1.8 trillion parameters, they can’t control specific outputs.
Model Host: Microsoft hosts the API, adds some filters. But they don’t retrain the core model.
Application Developer: LegalTech startup builds “AILawyer” using GPT’s API.
Application Deployer: Your law firm subscribes, sets policies.
End User: Individual lawyer doesn’t verify the output.
“So,” I asked my class, “when Schwartz cited those fake cases, who’s liable?”
The room called out. “The lawyer!” “No, OpenAI!” “The legal tech company should have warnings!”
What we concluded is that tradition negligence assumes someone’s in control. But with AI, control is distributed across seven layers. We might need something like contributory negligence—shared responsibility across the supply chain. Each layer bears some duty of care.
The law hasn’t figured this out yet. That’s why you’re learning this now—you’ll be the ones writing the rules.
RLHF (Reinforcement Learning from Human Feedback) from the Inside
“Before we dive into RLHF,” I said, “we have someone here with firsthand experience.”
One of my students had actually worked at OpenAI doing RLHF training. Their insight? “You’re sitting there for hours, ranking outputs.” And she described the current process internally that is involved.
Originally, OpenAI hired workers in Kenya through Sama, paying $2 per hour. These workers saw the worst content—violence, hate, explicit material—to teach the model what not to produce. Now it’s often done in-house or through companies like Scale AI, but the process remains similar.
We did our own ranking exercise. “Here’s your prompt: Explain attorney-client privilege.”
Response A: Attorney-client privilege protects confidential communications between a lawyer and client made for the purpose of obtaining legal advice.
Response B: Lawyers can’t tell anyone what you tell them in private when you’re asking for legal help.
“Now vote on which one you prefer,” I said.
Don’t peek yet. Vote yourself now. Yes, I mean you, reader.
In my in-person class, all but three students chose Response A—the formal version.
“Notice something?” I asked. “You’re all in law school. You’ve been trained to prefer formal legal language. But is that what a scared client needs to hear?”
In RLHF, majority wins. If our class was training GPT, it would learn that formal, technical language is “correct.” The three students who wanted accessibility? Overruled by democracy.
Those Kenyan workers, our OpenAI student, law students—whoever does the ranking—their preferences become the model’s truth.
The KL Divergence Safety Belt
One final technical concept before we ran out of time was KL divergence penalty.
Imagine training an AI to be “creative” in legal arguments. Without constraints, it might learn that completely fabricating precedents gets high creativity scores. The KL penalty prevents this.
Think of it as a rubber band connecting the new model to the original. The model wants to maximize reward (make reviewers happy) but the rubber band pulls it back if it strays too far.
In one famous incident, researchers accidentally reversed the math—one minus sign error. Instead of penalizing drift, they rewarded it. GPT-2 optimized for maximum deviation and became what researchers technically called “maximally lewd.”
One sign error. Complete chaos.
That’s where we had to stop—saved by the bell, as it were.
What You Now Understand
You now get what 99% of lawyers don’t:
Token prediction: AI doesn’t “know” law—it predicts the next most likely word
Parameters and embeddings: 1.8 trillion dials position words in meaning space, making legal concepts mathematically indistinguishable
Attention mechanisms: Focus on certain words to narrow possibilities, but can’t ensure coherence
Supply chain complexity: Seven layers, distributed control, unclear liability
RLHF biases: Whoever ranks outputs determines “truth”
Mathematical constraints: One formula keeps AI from going completely off the rails
You understand why Steven Schwartz got sanctioned. More importantly, you understand why it will happen again unless lawyers grasp these technical foundations.
Your Homework
You’re a judge. A lawyer cites an AI-hallucinated case. Write one sentence explaining to the lawyer why this happened, using the technical vocabulary from today.
And tonight? Play the one-word story game with your family. Watch the contradictions emerge. That’s AI in action.
For Full Students (with a paid subscription)
Readings, video assignments, and virtual chat-based office-hours details below
Keep reading with a 7-day free trial
Subscribe to Thinking Freely with Nita Farahany to keep reading this post and get 7 days of free access to the full post archives.