

8:55 a.m., Wednesday. Welcome back to Professor Farahany’s AI Law & Policy Class. (Note that next week if Fall Break, so our next class is on October 20. Take the week to catch up on classes that you’re behind on!)
First, the cold call. If all you have time for today is two minutes, here’s a quick recap of what we’re covering in today’s class:
In its copyright lawsuit against OpenAI, the New York Times showed how ChatGPT could reproduce their copyrighted articles verbatim. How did OpenAI respond? They accused the NYT of “hacking” their system and sought to dismiss some of their claims for violating their terms of service.

Which means the very act of discovering AI vulnerabilities—whether for copyright, safety, or security purposes—can be legally attacked as “hacking,” “circumvention,” or breach of contract by companies. Putting the very researchers who might discover risks in AI systems at legal risk of their own. The NYT, with its legal resources, can defend itself. But what about an independent researcher or grad student who finds similar problems and wants to disclose it publicly? Can they afford to do so?
Consider this your official seat in my class—except you get to keep your job and skip the debt. Every Wednesday, you asynchronously attend my AI Law & Policy class alongside my Duke Law students. They’re taking notes. You should be, too. And remember that the live class is 85 minutes long. Take your time working through this material.
Just joining us? You really should go back to Monday’s Class XII where we explored the technical side of adversarial testing. We discovered that AI systems like Claude can detect when they’re being tested. Today? We’re tackling the legal and policy framework—where technical practice meets law.
Today, we’ll explore why red-teaming is legally dangerous (our laws weren’t written for this), who should be allowed to red-team (the access problem nobody wants to discuss), whether there are any legal requirements to DO anything about it once problems are found, and how different states and governments are answering these questions (badly, but in fascinatingly different ways).
I. Understanding the Current Legal Landscape
If you picked “all of the above,” congratulations—you understand the minefield. If you picked the last option, at least you’re honest, and don’t worry, we’re going to cover what these laws are. So let’s start by looking at why testing AI for safety might land you in federal prison.
The Computer Fraud and Abuse Act (CFAA)
The CFAA is a 1986 federal law originally written to prosecute hackers. Yes, 1986—when “computer” meant a beige box and the internet was something only universities had. It makes it a crime to access a computer “without authorization” or to “exceed authorized access.”
In Van Buren v. United States (2021), the U.S. Supreme Court narrowed what “exceeding authorized access” means, but the boundaries for adversarial testing remain ambiguous. If you are a researcher who is testing for vulnerabilities in AI systems, this arguably violates the Terms of Service of those companies, and courts haven’t ruled on whether this is a CFAA violation when AI researchers do so. The maximum penalties? A cool $500,000 fine and 5 years in prison for your first offense.
Shayne Longpre and colleagues, in their paper, A Safe Harbor for AI Evaluation and Red Teaming, identify CFAA exposure as a credible deterrent that needs a safe harbor solution (a way to legally protect people who are doing this important work).
The Digital Millennium Copyright Act (DMCA) § 1201
Section 1201 makes it illegal to “circumvent a technological measure that effectively controls access to a work.” For AI, the risk is wonderfully uncertain. It’s unclear whether safety filters qualify as “protection measures” or whether prompt injection or jailbreaking might be “circumvention.” No court has ruled on this for LLMs yet, which means you’re operating in legal limbo when you are ethically hacking an AI system. The penalties are the same as CFAA—up to $500,000 and 5 years in prison. At least they’re consistent.
Contract Law (Terms of Service)
Beyond criminal law, there’s civil liability. Every AI platform has Terms of Service that you probably didn’t read (be honest). Violating them is breach of contract. Companies can sue for damages and ban your account permanently if you detect an anomaly in their system and report it publicly (like I’m going to do here in a minute).
This creates a fascinating paradox where the people most qualified to find problems are legally prohibited from looking for them.
Quick Exercise: The Researcher’s Dilemma
You’re a security researcher who finds ChatGPT will reveal credit card patterns if prompted in base64 encoding. You want to publish this finding at DefCon (don’t remember what DefCon is? Go back to Class XII). Let’s walk through your legal risks: CFAA risk for exceeding authorized access via ToS violation, DMCA § 1201 risk if considered circumventing safety measures, breach of contract and civil liability from OpenAI. You could face criminal prosecution and/or civil lawsuit.
How many of you would still publish? Think about it before reading on. (If you said yes, please send me your lawyer’s contact info—they must be amazing.)
And from the Longpre et al. paper, here are the chilling effects they documented about all of this:
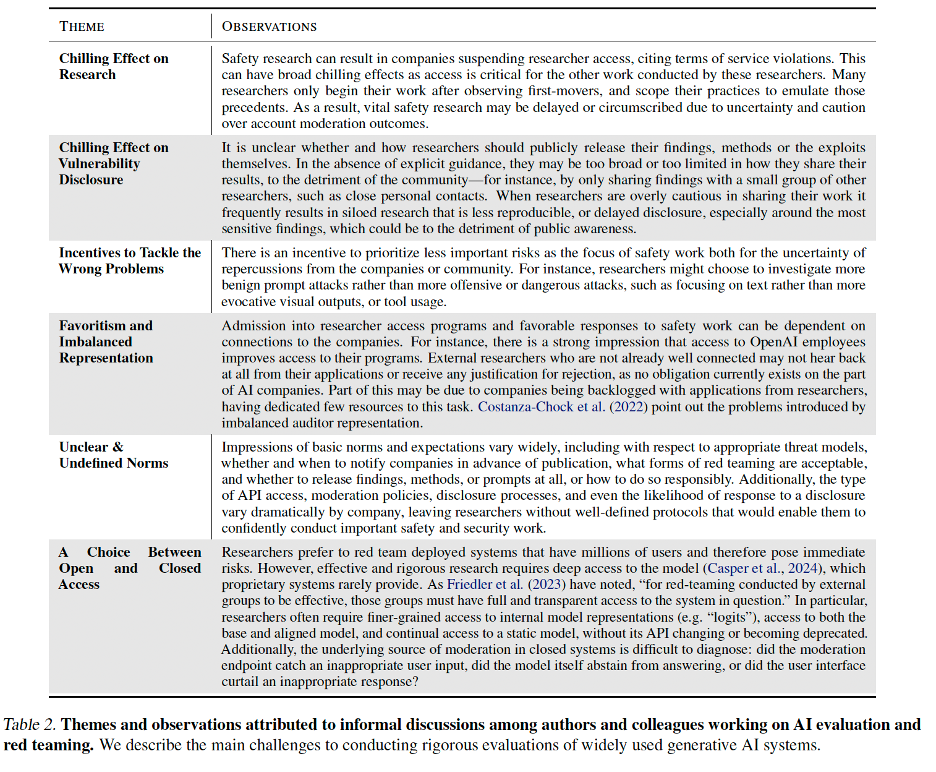
II. The Safe Harbor Solution
In the early 2000s, security researchers faced the same problem with software. Finding bugs in Windows could get you sued by Microsoft. The solution was “Coordinated Vulnerability Disclosure,” with clear policies about what constituted acceptable testing. The researchers propose we need the same thing here, with legal safe guards, technical safeguards (like not getting kicked out of the system), and good faith testing requirements by the researchers. Check out their paper for more details, and to get a closer look at Figure 1 that summarizes their proposal:
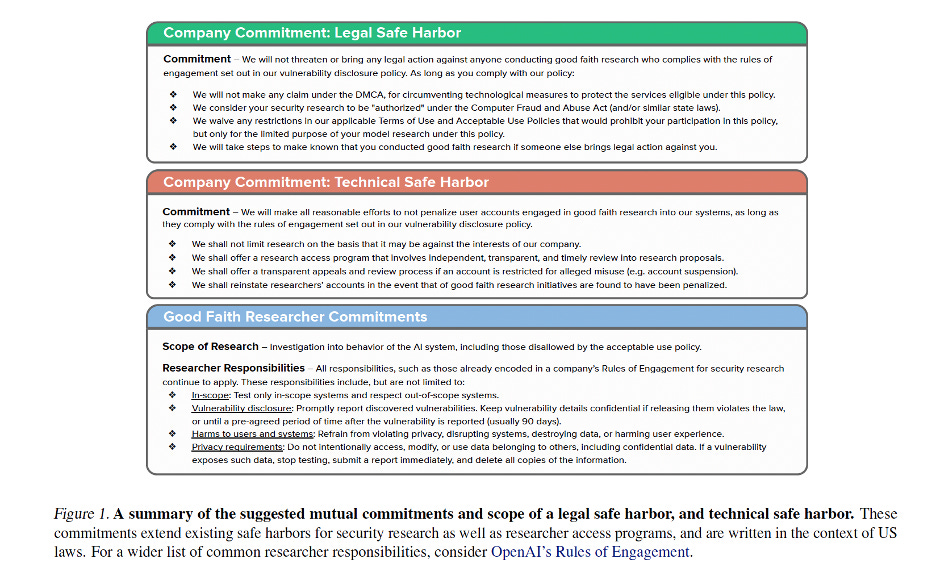
The proposal has two parts. Legal safe harbor would mean companies commit not to pursue legal action against researchers acting in good faith, with “good faith” based on published vulnerability disclosure policies including timely disclosure, no harm, and privacy safeguards—crucially, not at the company’s discretion. Technical safe harbor would mean no automated account suspensions for safety research, clear appeals processes, pre-registration systems for recognized researchers, and transparent standards.
But this creates a potential economic barrier—only well-funded organizations might afford systematic evaluation. The individual grad student researcher remains vulnerable. It’s creating a two-tier system of safety research: the haves who can afford to participate in official programs, and the have-nots who remain legally exposed.
On July 22, 2024, Senators Schatz, Lujan, Welch, King, and Warner sent OpenAI a letter with pointed questions: Does OpenAI allow independent experts to test pre-release? Will you involve independent experts in governance? Will you make models available to US Government for pre-deployment testing?
OpenAI responded July 31, 2024, with vague promises about their “Safety & Security Committee”—still not external to the organization (and do they sign an NDA? Are they paid? Do they have real or perceived conflicts of interests?). The Senators’ inquiry frames the key federal questions: transparency and oversight. But notice what they didn’t ask: “What will you do when testing finds problems?” Even Congress is avoiding the hard question.
III. U.S. State Approaches: California vs Texas
On Monday, we wrestled with defining red-teaming. Today, let’s see how California and Texas actually answered those questions in law. Take a minute to skim SB 53, and then we’ll do a deep statutory dive together. Then we’ll compare it with Texas’s approach to red-teaming for AI harms.
California SB 53: The Mandate Approach
Let’s dissect SB 53’s requirements. It applies to “frontier developers” (models trained with >10^26 operations)(if you don’t remember what a “FLOP” is, go back to Class #7 and review, then come back here), and “large frontier developers” (same plus >$500M annual revenue), covering both open and closed source models. They must test for “catastrophic risks” defined as mass casualties (>$500M damage or death/bodily harm), cyberattacks on critical infrastructure, weapon design assistance, and other comparable severe harms.
Notice what’s missing? The kinds of harms we are already seeing today. Like Individual harms, mental manipulation (check out my post on how big of a deal this is today), discrimination and bias in hiring or credit scoring, and interfering with democratic processes.
If you went back and looked at the definition of “catastrophic risk,” you should have answer (most likely) no to all three. The statute focuses on mass physical harm (remember when we talked about “p-doom”? It seems to be targeting some version of that).
And SB 53 is surprisingly vague about how testing must be conducted. Companies must report their testing procedures, risk assessment methods, mitigation measures, and third-party involvement (for large developers). But companies essentially grade their own homework.
When problems are found, normal risks must be reported within 15 days to the Office of Emergency Services. Imminent risk of death or injury? You’ve got 24 HOURS to do the reporting. There’s a public transparency report requirement before or concurrent with deployment, though companies can redact for trade secrets, cybersecurity, or public safety.
But here’s what’s shocking—and made your Duke Law counterparts visibly uncomfortable as they realized it—the law requires testing and disclosure but NOT remediation. You can find a catastrophic risk, report it, and deploy anyway.
But one more concern we shouldn’t overlook, is SB 53’s enforcement, which are civil penalties that max out at $1 million per violation with AG-only enforcement (no private right of action). OpenAI’s valuation is roughly $500 billion. One million dollars is 0.0002% of their value. That’s like fining someone making $100,000 about 20 cents. (One of your Duke Law counterparts tried to do the fast math for us on this. The math didn’t work out well on the fly, but they got the point, and hopefully you do now, too. It’s not much of a deterrent).
(On the bright side, the law DOES provide whistleblower protections for reporting AI risks, so at least ethical technologists can act in accordance with their consciences).
[Note: We’ll compare this to the EU AI Act’s approach to conformity assessments and the UK AI Safety Institute’s government evaluation model in our international governance module later in the semester.]
Texas HB 149: The Shield Approach
Texas took the opposite philosophy, focusing on specific harms like manipulation for self-harm, discrimination, social scoring, deepfakes, and privacy violations. The key innovation is Section 552.105(e): If you discover violations through “adversarial testing or red-team testing,” that discovery provides a defense against civil penalties. Texas recognizes that discovering violations through testing is responsible development, not something to penalize.
(On that note, does the Texas Law cover the character.ai suicide cases?)
They also created a Regulatory Sandbox Program (Chapter 553) where you can test AI with certain laws waived for up to 36 months. The attorney general can’t prosecute participants for violations during testing. It’s like Vegas for AI testing—what happens in the sandbox stays in the sandbox.
California says “you must test and tell us what you find (but you can still deploy).” Texas says “if you choose to test, we won’t punish you for what you find.” As a startup with limited resources, which would you choose?
IV. Federal Approaches: Two Competing Visions
Trump’s AI Action Plan (July 2025)
The plan focuses on red-teaming as national security, focusing on cyberattacks, CBRNE weapons (Chemical, Biological, Radiological, Nuclear, Explosives), and novel security vulnerabilities. CAISI at the Department of Commerce leads evaluation in partnership with agencies having CBRNE and cyber expertise. Testing happens in high-security data centers with results potentially classified. It focuses exclusively on national security risks, not ethics, bias, or social harms. If your AI discriminates in hiring, that’s not their problem. If it can design bioweapons, now we’re talking.
The Durbin-Hawley LEAD Act
This bipartisan legislation takes a completely different approach using products liability. Developers are liable if they fail to exercise “reasonable care” in design, with “design” explicitly including “training, testing, auditing, and fine-tuning.” It covers physical injury, financial harm, and emotional distress.
Instead of mandating testing like California or calling for government testing infrastructure for national security risks like the Trump plan, they adapt traditional products liability law to AI. The Act makes developers liable for harm if they fail to exercise “reasonable care” in the design of AI systems, and the definition of “design” explicitly includes “training, testing, auditing, and fine-tuning.”
So if you don’t adequately test your AI system and it causes harm, you face liability. The Act covers everything from physical injury to financial harm to emotional distress, with both developers and deployers potentially liable. There’s also a foreign developer registration requirement, which means if you’re making AI available in the US from abroad, you must designate a US agent for service of process.
The genius is that they don’t prescribe specific testing methods; they just make you liable if you don’t test adequately and something goes wrong. Given our discussion in Class XII of how difficult it is to define what red-teaming is, or agree on what to test in red-teaming, the LEAD Act puts the burdens on the companies to figure it out. It basically says, do whatever testing you think is necessary because if something goes wrong, we’re coming for you.
V. Concluding Thoughts
Today we’ve seen how AI red-teaming sits at a critical legal crossroads. Current law treats safety researchers as potential criminals, with CFAA, DMCA, and Terms of Service violations creating a chilling effect that deters the very testing we need for AI safety. In response, we’re witnessing a scramble for solutions across every level of governance. Longpre and colleagues propose voluntary safe harbors borrowed from cybersecurity, hoping companies will protect good-faith researchers.
California has taken the regulatory path, mandating testing and disclosure with million-dollar penalties for non-compliance. Texas flipped the script entirely, making red-teaming a shield against liability rather than an obligation. At the federal level, we see both the Durbin-Hawley LEAD Act’s products liability approach and the Trump Administration’s plan to essentially nationalize testing through defense and intelligence agencies.
Yet despite all these frameworks, none adequately answers the fundamental question: when red-teaming finds unfixable problems, then what? We can mandate testing, incentivize it, or nationalize it, but we still haven’t figured out what to do when we discover that an AI system’s most dangerous capabilities can’t be removed without destroying its usefulness. This is the governance challenge of our time – we’re requiring or encouraging the discovery of problems we don’t yet know how to solve.
Your Homework:
Share this post with ONE person you think would benefit from learning more about AI red-teaming
Read these two things today: (1) My post on
about AI ChatBots and the First Amendment, and (2) Vince Conitzer and colleagues new paper about AI Testing Should Account for Sophisticated Strategic Behaviour.
The entire class lecture is above, but for those of you who found today’s lecture valuable, and want to buy me a cup of coffee (THANK YOU!!), or who want to go deeper in the class, the class readings, video assignments, and virtual chat-based office-hours details are below.
Keep reading with a 7-day free trial
Subscribe to Thinking Freely with Nita Farahany to keep reading this post and get 7 days of free access to the full post archives.