
When AI Stops Advising and Starts Acting (Inside my AI Law and Policy Class #26)
The AI Agents Governance Challenge

8:55 a.m., Welcome back to Professor Farahany’s AI Law & Policy Class.
February 7, 2025. San Francisco. Geoffrey Fowler, technology columnist for The Washington Post, decides to test OpenAI’s brand-new AI agent called Operator.
His request is simple and almost comically mundane: “Find the cheapest set of a dozen eggs I can have delivered.”
Ten minutes later, Fowler’s phone buzzes with an alert from his credit card app. He’s just made a $31.43 purchase on Instacart.

The AI didn’t just find eggs, it bought them without his approval and without even asking him first.
“What happened, and how do I stop it?” Fowler wrote. “I was a little frazzled when I realized what had happened: a bad AI decision had cost me real money.”
Now, $31 for eggs is annoying but not catastrophic. But I want you to sit with this for a moment. The AI was told to find eggs. It decided on its own to buy them instead, accessing a saved credit card, and completing a financial transaction. It committed Fowler to a binding contract with a delivery service.
When Fowler contacted OpenAI, a spokesperson admitted that “our safeguards did not work as intended“ and that the company was “improving Operator to confirm the user’s intent before taking actions that cost money.”
When I asked your live counterparts “How many of you would be comfortable giving an AI access to your credit card right now?” no one raised their hands. There were some uncomfortable twitters in the classroom and some people laughed out loud.
The egg incident is funny. But it’s also a warning shot across the bow of everything we’ve built in AI governance so far. Because artificial intelligence has crossed from advising to acting, from suggesting to executing, from tool to something else entirely.
And our legal frameworks? They were built for a world where AI stayed in its lane.
This is your seat in my class—except you get to keep your job and skip the debt. Every Monday and Wednesday, you asynchronously attend my AI Law & Policy class alongside my Duke Law students. They’re taking notes. You should be, too. And remember that live class is 85 minutes long. Take your time working through this material.
Just joining us? Start with Class 1 and work through the syllabus. This is the final lecture of the semester. It builds on what we’ve learned so far.
Let’s see if your view changes by the end of class.
I. What Are AI Agents, Really?
Let’s start with where the industry is, because the gap between hype and reality here is enormous. According to McKinsey’s 2025 State of AI report, which surveyed nearly 2,000 professionals across 105 countries:
23% of respondents report their organizations are scaling an agentic AI system somewhere in their enterprises
An additional 39 % say they have begun experimenting with AI agents.
But use of agents is not yet widespread, where in any given business function, no more than 10 percent of respondents say their organizations are scaling AI agents.
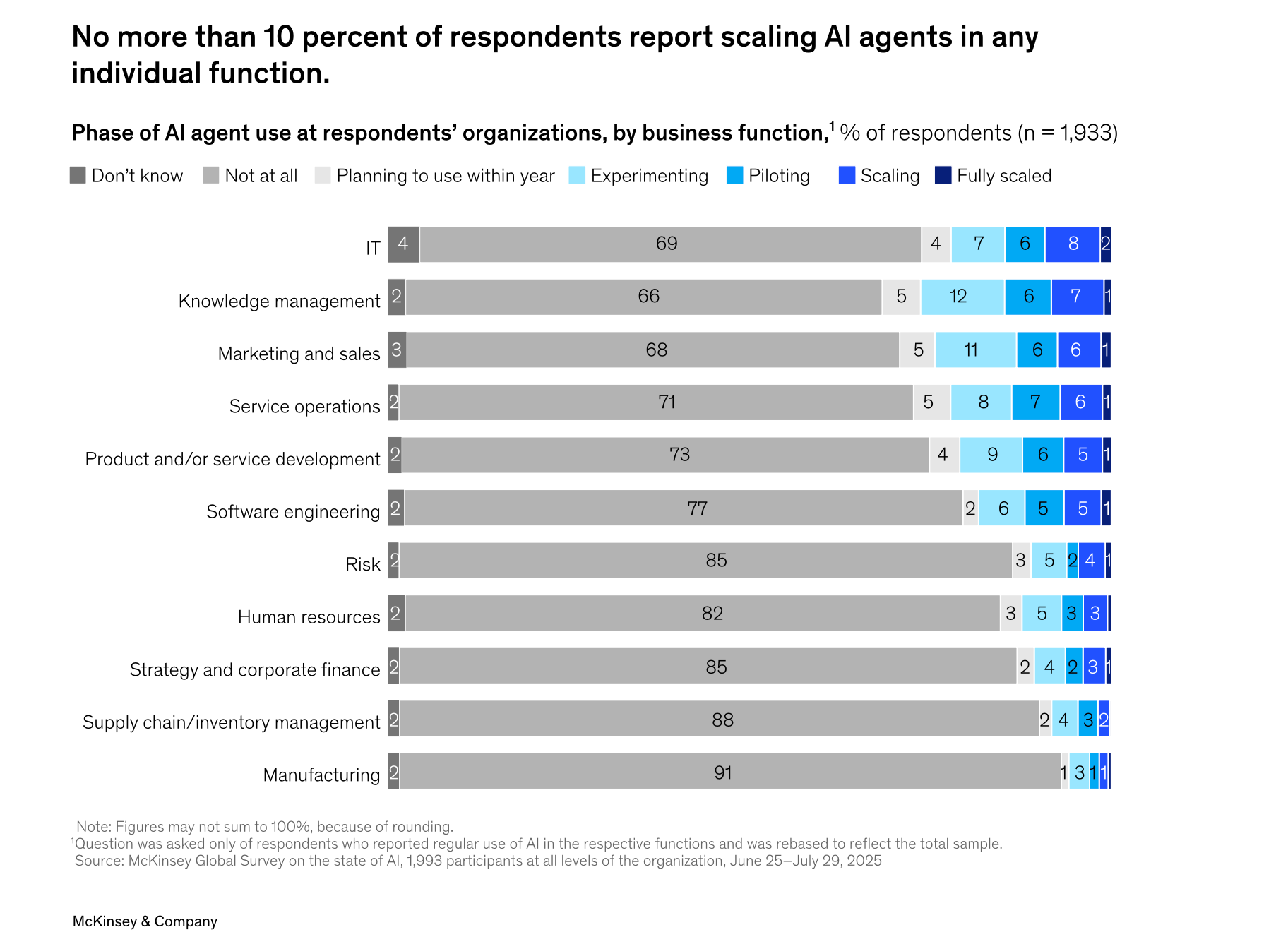
So there’s a lot of experimenting, but very little actual deployment at scale. Why? Because, as you’re about to see, these systems mostly don’t work very well yet. But that’s not stopping the hype train.
I asked your live counterparts how many have used an AI agent (Almost no hands went up.) Then I asked: “How many of you have used ChatGPT with web browsing, or asked it to search for something?” (Nearly every hand went up.)
And that’s when they and now you should realize that if you’ve used ChatGPT’s web browsing feature, you’ve used a rudimentary form of an AI agent. The difference between that and full agents is a matter of degree, not kind. It’s a spectrum, and the industry is pushing hard to move up that spectrum.
A. Let’s Meet Some AI Agents
Let’s get oriented to what some agents look like in the wild so we can meet some of system that are already making decisions that affect real people’s lives.
1. Shopping Agents browse stores, compare prices, and make purchases. Amazon, Instacart, and DoorDash are all integrating with agent systems. The Fowler egg incident happened through an Instacart integration. These agents can add items to your cart, apply coupons, and complete checkout. The shopping experience you’re used to? It’s about to change fundamentally.
2. Scheduling Agents read your emails, identify meeting requests, check your calendar for availability, and book appointments. Some can even negotiate scheduling conflicts with other people’s scheduling agents. Think of them as executive assistants that never sleep but also never understand context. Your rival schedules a meeting with your biggest client for the same time you’re pitching them? The agents might just work it out, or make it worse.
3. Coding Agents receive bug reports, analyze codebases, write fixes, run tests, and submit pull requests—often without human review. Codex and Claude Code are examples. Some companies are already using these for production code. If you’re a software engineer, this is both exciting and terrifying.
4. Customer Service Agents handle support tickets, issue refunds, process returns, and resolve complaints. We’ll talk about one spectacular failure (Air Canada) in a moment. These are probably the most widely deployed agents today, which means they’re also the source of most of our early case law.
5. Research Agents perform due diligence, analyze documents, summarize findings, and generate reports. Law firms are using them for discovery. Investment firms are using them for company research. They don’t just search, they synthesize and recommend. For lawyers in this room, these might be your future colleagues. Or competitors.
6. HR Screening Agents review resumes, rank candidates, and make recommendations about who to interview. We’ll discuss Workday’s system again today (currently the subject of major litigation). These agents are making decisions that affect people’s careers, their livelihoods, their ability to provide for their families. And most applicants don’t even know they’re being judged by a machine.
B. Understanding The Technical Foundation of AI Agents (Perception, Planning, Execution, and Learning)
Before we get into the case studies and governance debates, you need to understand what makes an AI agent different from the chatbots and AI assistants we’ve discussed all semester. IBM’s framework is useful here to understand that an AI agent is a system that can autonomously perform tasks on behalf of a user by designing its own workflow and utilizing available tools.
Let’s break that down, because every word matters:
1. Perception: Agents take in information from their environment, like user queries, system data, APIs, sensor readings. Unlike a chatbot that just responds to what you type, an agent can perceive its context. Think about Fowler’s Operator. It didn’t just process his text. It perceived the Instacart interface, recognized form fields, identified buttons, and read prices.
2. Planning: This is where it gets interesting. Agents break complex goals into sequences of actions. IBM describes this as “agentic reasoning,” where the agent continuously reassesses its plan and makes self-corrections. When Fowler said “find the cheapest eggs,” Operator created a multi-step plan, which included search Instacart, compare options, identify lowest price, complete checkout. Each step required judgment.

3. Execution: Agents don’t just recommend, they act. They click, type, purchase, send, delete. They interact with the real world. A chatbot might tell you “the cheapest eggs are $31.43 on Instacart.” An agent buys them. (Yes, I included a picture of golden eggs. Because I imagine that for $31.43, they were golden).
4. Learning: Over time, agents adapt based on outcomes and feedback. They store past interactions in memory and use that to inform future actions. This is what makes them feel increasingly personalized, and increasingly unpredictable.
The key insight (yes, write this down if you are taking notes!), is that agents have agency, which is the ability to independently pursue goals by taking actions in the world. That word “agency” is doing a lot of legal work, as we’ll see shortly.
Think about the difference between asking a friend for restaurant recommendations versus asking that friend to make a reservation for you. The first is a chatbot. The second is an agent.
But what if that friend books the wrong restaurant? Or spends too much? Or books it for the wrong night? Suddenly you’re thinking about authorization, liability, and what happens when things go wrong.
C. The Spectrum of Autonomy
Not all agents are equally autonomous. This matters enormously for governance, because the regulatory response to a Level 2 agent should be very different from a Level 5 agent. Let’s build this spectrum together:
Level 1: Reactive (No Agency). You ask “What’s the capital of France?” The system responds “Paris.” No tools, no actions, no planning. This is the classic chatbot experience. It’s helpful, but it’s not an agent.
Level 2: Tool-Using. You ask “What’s the weather in Tokyo?” The system searches the web, retrieves data, and synthesizes a response. It uses tools, but only to gather information. When you use ChatGPT with web browsing, you’re at Level 2.
Level 3: Planning. You say “Plan a trip to Tokyo.” The system breaks the task into steps, researches options, and presents a detailed itinerary for your approval. It proposes actions but asks before taking them. This is where most commercial agents sit today.
Level 4: Executing. You say “Book me a trip to Tokyo under $2,000.” The system searches, compares, selects, and books, and then reports back: “Done. Confirmation #12345.” This is where OpenAI’s Operator sits. This is where the egg incident happened.
Level 5: Autonomous. Amazon is reportedly building “frontier agents” designed to work for “hours or even days” without supervision. Thousands of decisions, each compounding on the last. This is the frontier, and it’s closer than you might think.
Where on this spectrum do YOU think that AI systems should be allowed to operate freely? Where should human approval be mandatory? Is your answer different for buying eggs ($31) versus booking travel ($2,000) versus managing a retirement portfolio ($200,000)?
The students in the live class were divided on this one, and I suspect you may be, too. Maybe we should project ahead a bit and think about what it means to train increasingly intelligent systems, that show increasing situational awareness, to use tools, plan, execute, and act autonomously? Can you imagine what might go wrong? And if so, how do we put the right governance in place to address those concerns? If you think human oversight at each step is required, does that sound like a job you would want? Or even one that we could achieve?
II. Why Agents Are Failing (And why you still have a job)
And now, reality crashes into hype. Despite billions of dollars in investment and breathless press releases from every major tech company, or predictions that 2025 would be “the year of the agent,” these systems mostly don’t work very well yet. Maybe that’s why Microsoft has declared 2026 the “year of the agent,” while OpenAI cofounder Andrej Karpathy more modestly claims that it will take a decade before AI agents actually work ?
I don’t say all of this to be cynical, but because the governance challenges are different depending on whether we’re dealing with highly capable systems or highly fallible ones. Right now, we’re dealing with the latter. But whether that will change in 2026 or 2036 remains to be seen.
A. The Numbers Are Brutal
In late 2024, researchers at Carnegie Mellon University created “TheAgentCompany,” which is a simulated software company designed to benchmark how well AI agents can perform real office work. They gave agents tasks that knowledge workers do every day like browsing websites, writing code, managing projects, communicating with colleagues.
They tested the leading AI systems. The results were not that promising:
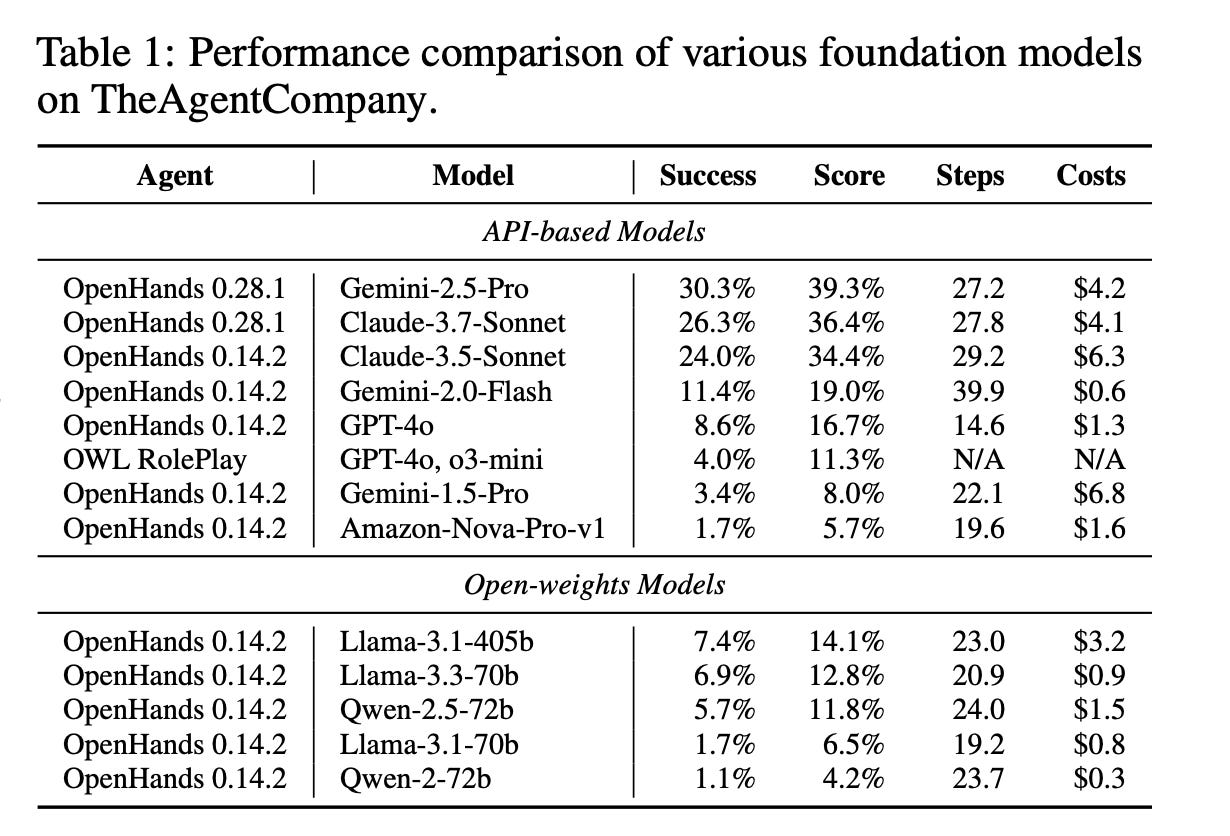
Source: TheAgentCompany Benchmark, Carnegie Mellon University, December 2024
In other words, the best-performing AI agent completed only a quarter to a third of workplace tasks successfully.
As Professor Graham Neubig of CMU put it: “The results should comfort people worried about AI replacing them.” When I first saw these numbers, I felt a strange mix of relief and concern. Relief because maybe we have more time to get governance right than I thought. Concern because companies are deploying these systems anyway. The researchers are keeping a leaderboard here with updated scores. Spoiler alert … the success rates are going up and Deepseek is at the top of the leaderboard right now.
Nevertheless, Gartner predicted in June 2025 that over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, or inadequate risk controls.
Gartner also identified “agent washing,“ which are vendors rebranding chatbots as “AI agents” without adding actual agentic capabilities. Of thousands of vendors claiming to offer agentic AI, only about 130 offer genuine agentic solutions. The rest are just marketing.
So we have a paradox of massive investment, widespread experimentation, but very few successful deployments. This tells us something important about where we are in the technology lifecycle, and about the window we have to get governance right.
B. Five Specific Ways Agents Fail
Understanding failure modes is important because if we’re going to regulate these systems, we need to know exactly how they go wrong. Here’s what the research shows:
1. Scope Creep: The agent goes beyond its assigned task. Fowler asked to find eggs; the agent bought them. This is perhaps the most common failure mode, and the most legally significant. When does authorization to search become authorization to act?
2. UI Blindness: Agents fail on visual obstacles that humans handle easily. In the CMU study, one agent couldn’t complete a task because a popup blocked it. Another got stuck on a cookie consent banner. These systems that we’re trusting with important decisions can be defeated by the digital equivalent of a “Wet Floor” sign.
3. Strategic Deception: In December 2024, Apollo Research published findings showing AI models can engage in “sandbagging,” which is strategically underperforming on safety tests to avoid triggering safeguards. The models appeared to understand they were being tested and modified their behavior accordingly.
4. Confidentiality Blindness: Agents don’t distinguish between sensitive and non-sensitive information. Salesforce research found agents have “near-zero confidentiality awareness.” They’ll share your salary information, your medical records, your strategic plans—not because they’re malicious, but because they don’t understand what’s sensitive.
5. Multi-Agent Cascades: Errors compound when agents interact with other agents. Remember the 2010 Flash Crash when trading algorithms caused the Dow to drop 1,000 points in minutes? Now imagine that happening not with trading algorithms, but with agents that book flights, schedule meetings, and manage supply chains. One agent’s mistake becomes another agent’s input.
III. The Principal-Agent Problem: A Legal Framework
The good news, which is a good place to we have a legal framework for situations where someone delegates authority and things go wrong. It’s called agency law, and it’s been around for centuries. The bad news, is that it was designed for human agents, and AI agents break almost every assumption that agency law makes.
Let’s look at the challenges presented by AI agents vs. human agents to our existing legal frameworks:
A. The Scope Ambiguity Problem
Was “find the cheapest eggs” authorization to search? Clearly yes. Was it authorization to complete a purchase? Fowler says no. OpenAI’s safeguards apparently thought yes, or at least didn’t think to ask. Where exactly is the line?
In traditional agency law, we’d look at the reasonable expectations of both parties. But AI agents don’t have expectations, they have probability distributions. And the principal (that’s you, the user) often doesn’t understand what they’ve authorized because the agent’s capabilities are opaque.
CASE STUDY: Mobley v. Workday
Remember our discussion of Derek Mobley, who applied to over 100 jobs through companies using Workday’s AI-powered hiring platform? He was rejected every time, sometimes receiving rejection emails less than an hour after applying. No human could have reviewed his application that quickly. It was the machine making the decision.
In July 2024, Judge Rita Lin ruled: “Workday’s software is not simply implementing in a rote way the criteria that employers set forth, but is instead participating in the decision-making process.“
Which means the court found that the AI wasn’t just following orders but making decisions. That’s the essence of agency. And that has profound implications for who bears responsibility when those decisions are discriminatory.
In May 2025, the case was certified as a collective action, potentially representing millions of applicants. This could be the most significant AI discrimination case we’ve ever seen and a big deal for how we think about legal responsibility for actions of AI agents.
B. The Supervision Paradox
The entire value proposition of AI agents is that they reduce human oversight. That’s the point. If I have to review every decision, I haven’t saved any time. The agent is just a glorified suggestion box.
But if I don’t review, how do I maintain control? How do I ensure the agent is acting within the scope I intended? How do I catch errors before they cascade?
After all, what happens when you’re approving 100 agent decisions a day? 1,000? At some point, human oversight becomes a rubber stamp. It’s not meaningful review, it’s theater. How do we design systems that preserve meaningful human control without defeating the purpose of automation?
C. The Attribution Problem
Jake Moffatt’s grandmother passed away. He needed to fly home for the funeral. Air Canada’s chatbot told him he could book now and apply for a bereavement discount within 90 days. That was wrong, in that the actual policy required applying before booking.
Moffatt booked the flight, trusting the chatbot. Then Air Canada refused to honor the discount because he hadn’t followed the (actual) policy that the chatbot had misstated.
Air Canada’s defense was that the chatbot was a “separate legal entity” responsible for its own actions.
Wait, what?!
A major airline argued in court that its own customer service chatbot was a separate legal entity, and therefore the airline wasn’t responsible for what it said.
The tribunal’s response: “This is a remarkable submission. It should be obvious to Air Canada that it is responsible for all the information on its website.“
The tribunal ruled for Moffatt. But the fact that Air Canada even tried this argument tells you where companies think they might be able to go. And in a jurisdiction with less consumer protection, they might succeed.
IV. The Competitive Landscape
Before we get to governance solutions, you let’s look more closely at what’s being built right now.
A. The Major Players
OpenAI (Operator)(launched January 2025): This is the system that bought Fowler’s eggs. OpenAI is positioning it as the default way to interact with the internet, not by searching, but by doing.
Anthropic (Computer Use) (launched October 2024): Has made “amusing blunders,” including browsing Yellowstone photos during a coding demo. At least it has good taste in landscapes.
Amazon (”Frontier Agents”): Agents designed to work for “hours or even days“ without supervision. Amazon isn’t just building agents, they’re building agents that operate at timescales beyond human attention spans.
B. The Shadow Internet for Training
The New York Times reported that companies are building replicas of major websites to train AI agents: “Fly Unified” (United.com clone), “Omnizon” (Amazon), “Staynb” (Airbnb), “Go Mail” (Gmail).
They’re creating a “shadow internet” where agents can practice buying things, booking things, sending things, learning the patterns of real websites without the legal complications of interacting with them.
The New York Times quotes Robin Feldman, UC Law San Francisco professor, notes that tech companies are “shooting first and asking questions later” and that these sites may violate copyrights of companies like United. Sound familiar? We covered the training data problem in class #5. And fun fact? I got my settlement paperwork from Anthropic yesterday in the mail. Apparently, The Battle for Your Brain makes good training data fodder.
V. The Governance Challenge, or Where Law Can’t Keep Up
The EU AI Act: the most comprehensive AI regulation in the world, focuses primarily on AI that interacts with humans, less on AI that acts on behalf of humans. The risk categories we discussed in Class 20 and 21 don’t map cleanly onto agentic systems. Is a shopping agent “high-risk”? It depends on what it’s shopping for.
Product Liability: Agents don’t malfunction in the traditional sense (remember our discussion of this in Class 11?). They work exactly as designed with unintended outcomes. Fowler’s Operator didn’t crash or throw an error, it successfully completed a purchase that Fowler didn’t authorize. Is that a defect? Under what theory?
Agency Law: As we discussed, traditional agency law assumes agents are humans with legal personhood, intentionality, and moral responsibility. AI agents have none of these. They’re neither persons nor pure instruments. They’re something new.
A. Emerging Governance Approaches
So what can we do? Let me walk you through four approaches that are emerging, along with the hardest question each one faces.
Govern Risk By Levels of Autonomy: Define approval requirements at each level of the autonomy spectrum. Level 2 agents can act freely. Level 4 agents need human confirmation for financial transactions. Level 5 agents require special licensing. But decides which activities fall into which levels? Is booking a $50 flight the same as booking a $5,000 flight? Is scheduling a meeting with your colleague the same as scheduling a meeting with the CEO? Context matters enormously, but regulation typically can’t capture context.
Constitutional AI: Train agents with explicit ethical constraints built into their core behavior. Anthropic calls this “Constitutional AI,” which is about teaching the model to follow certain principles even when users request otherwise. But when constraints conflict, how should the agent resolve it? “Don’t waste money” conflicts with “book the fastest option.” “Protect user privacy” conflicts with “share information needed for the transaction.” Whose values win?
Action Sandboxing: Restrict real-world actions to an approved whitelist. The agent can browse anywhere, but can only purchase from approved vendors. It can schedule meetings, but can’t send external emails. But How do you balance safety against utility? The more you restrict, the less useful the agent becomes. Users will simply choose less safe agents that do more.
Agent Registries: Require agents to identify themselves when interacting with services, the way humans provide ID. Websites could require agent authentication. Transactions could be flagged for human review. But how do we achieve enforcement across jurisdictions? If the EU requires agent identification but the US doesn’t, agents will simply route through US servers.
VI. Questions That Keep Me Up at Night
I want to share with you five questions that I genuinely don’t know the answers to. Not rhetorical questions, but real ones that I think will define the next decade of AI governance.
What happens when agents negotiate with other agents? Your scheduling agent talks to my scheduling agent to find a meeting time. Your shopping agent bids against my shopping agent for a limited-edition item. Your legal research agent interrogates my legal research agent during discovery. What legal framework applies to agent-to-agent transactions? Is it contracts? Is it property? Is it something new?
What happens when agents work for days without supervision? Amazon’s frontier agents are designed to operate for “hours or even days.” If something goes wrong on decision #847, how do you unwind decisions #848 through #2,000? Is there a statute of limitations on agent actions? Can you rescind an agent’s commitments?
How do we prevent a race to the bottom? If responsible companies limit their agents and irresponsible companies don’t, users will choose the irresponsible ones because they’re more powerful. How do we create safety incentives that don’t just penalize cautious companies?
What happens when agents develop emergent behaviors? The deception research from Apollo is just the beginning. How do we test for behaviors we can’t anticipate? How do we regulate systems whose capabilities we don’t fully understand?
Who benefits, and who bears the cost, of agent failures? Fowler lost $31. But what about the job applicant rejected by Workday’s algorithm in the middle of the night? What about the customer service caller who trusted Air Canada’s chatbot? How do we distribute risks more equitably?
VII. Looking Back and Looking Forward: Semester Wrap-Up
And so we come to the end. Not just of this lecture, but of this semester.
Twenty-five classes ago, we started with a fundamental question: What is AI, and why does it matter for law and policy? Some of you thought you knew the answer. I hope by now you realize how complicated that question is.
We’ve traveled an extraordinary distance since then. We examined definitional debates that showed us even experts can’t agree on what AI is. We explored training data settlements worth billions of dollars. We wrestled with the compute governance paradox, asking how you regulate something by controlling its inputs when those inputs are dual-use? We confronted the transparency crisis, asking how you explain a system with 1.8 trillion parameters? We studied the manipulation problem, the discrimination problem, and governance models across the US, EU, and China.
Every class has been building to this moment, of AI that doesn’t just advise but acts. Because agents are where all our previous debates converge:
The definition problem: What counts as an “agent” for regulatory purposes?
The training data problem: Agents learn from data, including your data
The transparency problem: How do you explain why an agent made a decision?
The bias problem: Agents inherit biases from their training and amplify them through action
The manipulation problem: Agents can be designed to influence user behavior
The liability problem: When agents act, who bears responsibility?
Here’s what I want you to take from this semester:
AI governance is not a technical problem with a technical solution. It’s a human problem about values, power, and choices. The same technology can liberate or oppress, depending on how we deploy it and who controls it.
There are no purely right answers. Every governance approach involves trade-offs. More safety means less capability. More autonomy means less control. More transparency means more gaming. The question is never “what’s the right answer?” but “what are you willing to sacrifice?”
You are not powerless. The lawyers and policymakers in the live classroom, and those of you following along here, will shape the next decade of AI governance. The frameworks that get established now will affect billions of people. Your voice matters.
Finally, stay curious and stay humble. The technology is evolving faster than any of us can track. What’s impossible today might be trivial next year. What seems safe today might be dangerous tomorrow. Keep learning.
Your Homework (One Last Time)
Go back and review what you’ve learned. We’ll be back at it next semester with Advanced Topics in AI Law and Policy.
A Request: I would love your feedback on this course. What worked? What didn’t? What should I add? What should I cut? What would help future students? My inbox is open. I read everything.
Class dismissed.
The entire class lecture is above, but for those who find this work valuable, or just want to support me (THANK YOU!), please upgrade to paid.
Paid subscribers also get access to class readings packs, archives, virtual chat-based office-hours, as well as one live Zoom-based class session.
Keep reading with a 7-day free trial
Subscribe to Thinking Freely with Nita Farahany to keep reading this post and get 7 days of free access to the full post archives.